发布日期:2025-12-15 18:08 点击次数:194
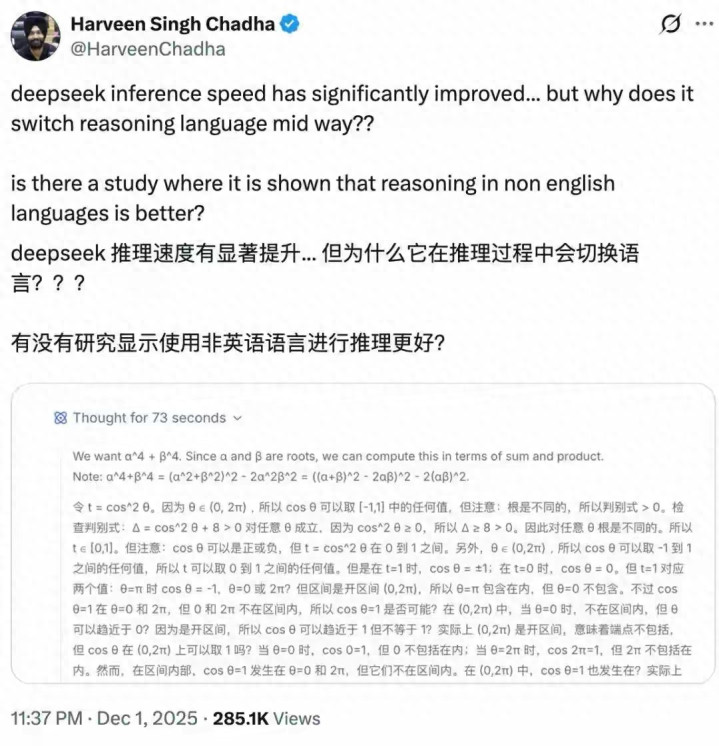
这篇文章讲述了一个有趣的现象:尽管DeepSeek模型在用英文提问时,仍会在思考过程中“切换”到中文(或其他非英语语言)思考。这引发了海外研究者和用户的疑问:为什么在用英文询问时,模型还是会用中文进行推理?这背后反映的是多语言模型在多语言推理中的一些深层次特性。
以下是对这个现象及其背后原因的分析总结:

中文的高信息密度:汉字每个字符携带的语义信息比拼音拼写的英文更丰富,这意味着用更少的token表达相同的意义。在推理过程中,为节省token,模型可能偏向更“紧凑”的中文表达。

多语言训练数据的影响:许多大模型在训练过程中,包含了大量中文语料。即使在用英文提问时,模型的潜意识或“思考习惯”中仍有中文的影子。这是因为模型的参数、语义空间和关联在多语言、多语料的背景下形成了交互。
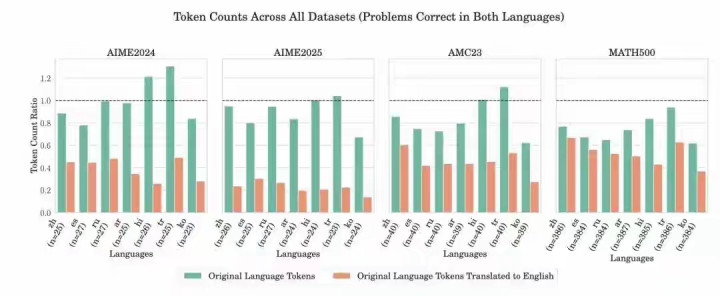
推理行为的语言依赖性:如微软的研究表明,在不同语言中进行推理,Token的节省效果显著。这表明模型在不同语言中“思考”的方式不一样,而中文在符合压缩和效率方面具有一定优势。

模型的内部语义转换机制:大模型在“思考”时,实际上并不拘泥于提问的语言,而是在其庞大的多语语义空间中进行推理。中文可能成为某些语义路径的优选途径,尤其当它能更高效地表示复杂的逻辑或推理内容时。
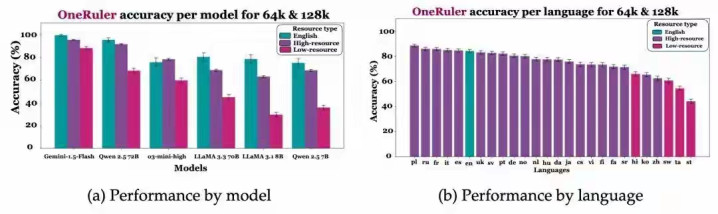
训练语料和目标任务的偏好:如果模型在训练中接触到更多中文样本,或者其设计、优化目标包含中文语料,就会出现“中文思考”的现象。这与模型在特定应用场景下的表现密切相关。

跨语言推理的效率优势:研究表明,非英语(特别是中文)在Token效率上具有优势,但这不等同于整体性能最优。不同语言在特定任务(如长上下文推理、逻辑推导)中的表现各异,影响模型的“思考”习惯。
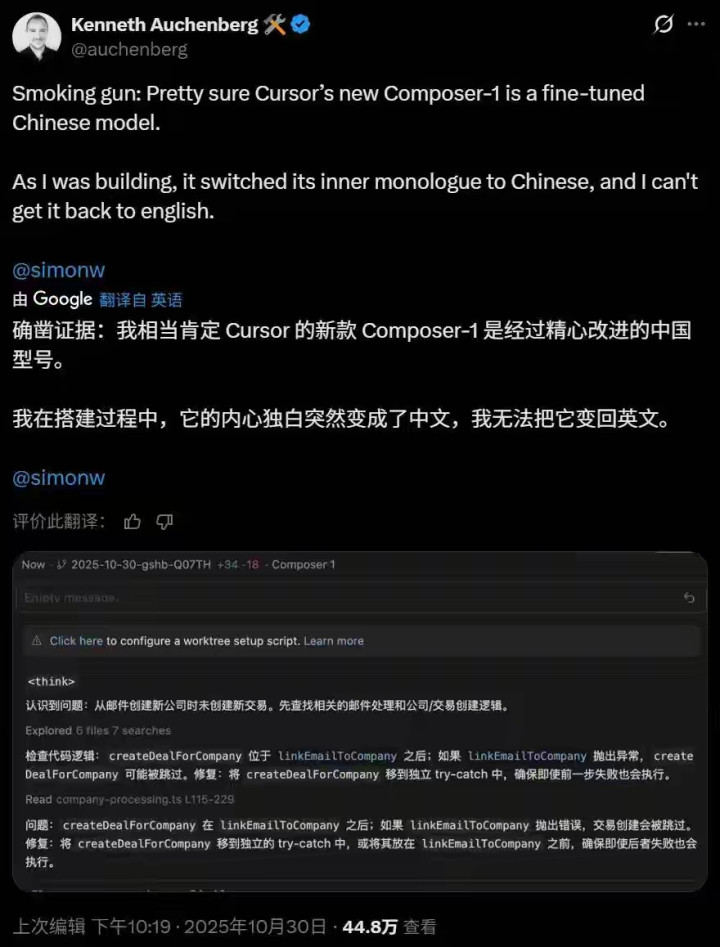
小结
“用英文提问,模型还在用中文思考”反映了当前多语言模型复杂的内在机制:模型的推理行为受训练语料、语言信息密度、Token效率等多重因素影响。这种现象不仅体现了中文在信息密度和压缩方面的优势,也揭示了多语言模型在多语言环境下的行为特性——它们的“思考”方式并非单纯遵循输入的语言,而是在多语种语义空间中选择最优路径。
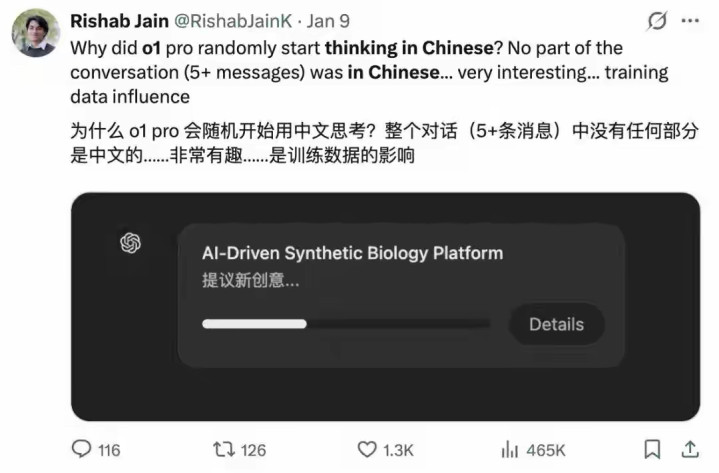
因此,未来如果希望模型在多语言推理中表现得更符合用户预期,还需要调整训练策略、优化语言平衡、强化多语言推理能力。这也是当前多语语言模型研究的重要方向。